
Road scene understanding from a monocular camera

🏆 Received best project award.
For more details - Project Report
The project is inspired by Tesla’s dashboard focusing on enhancing essential autonomous driving features contributing to the development of safer and more efficient ADAS technologies.
Leveraging deep learning techniques for autonomous driving, including YOLO, DETIC for object detection (cars, road signs, traffic signals), Marigold for monocular depth estimation, OSX for pedestrian pose estimation and mask RCNN for lane detection and classification and RAFT for optical flow to create a 3D representation of the driving scene. Integrated this data into Blender for visualization.
Overall pipeline
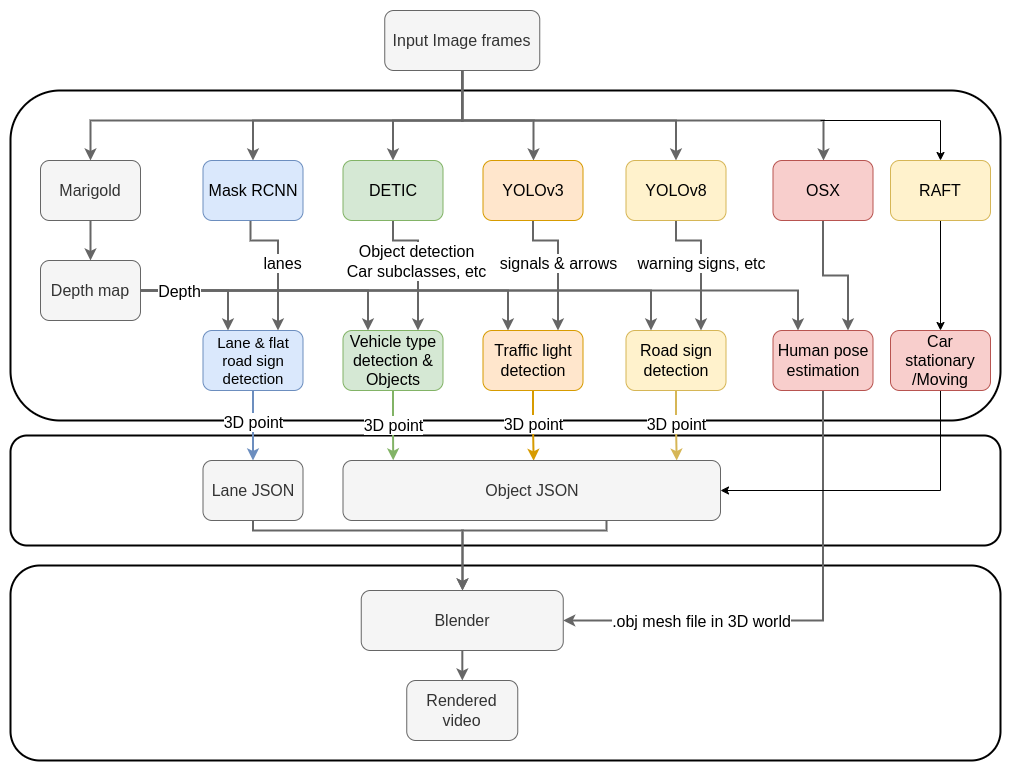
Monocular depth: Marigold
We utilized this model to get scaled depth following the instrutions on the github repo. We save these depth maps to project pixel coordinates to real world for the various detections.

Object Detection -> Instance Segmentation: DETIC
We utilized DETIC to do instance segmentation. We get car subtypes like SUV, sedan, hatchback, pickup_truck using custom vocabulary. We also get stop sign, motorcycle, bicycle, traffic cones, cylinder etc from this model. The centroid of these masks is then projected to 3D space using the depth from the previous model.

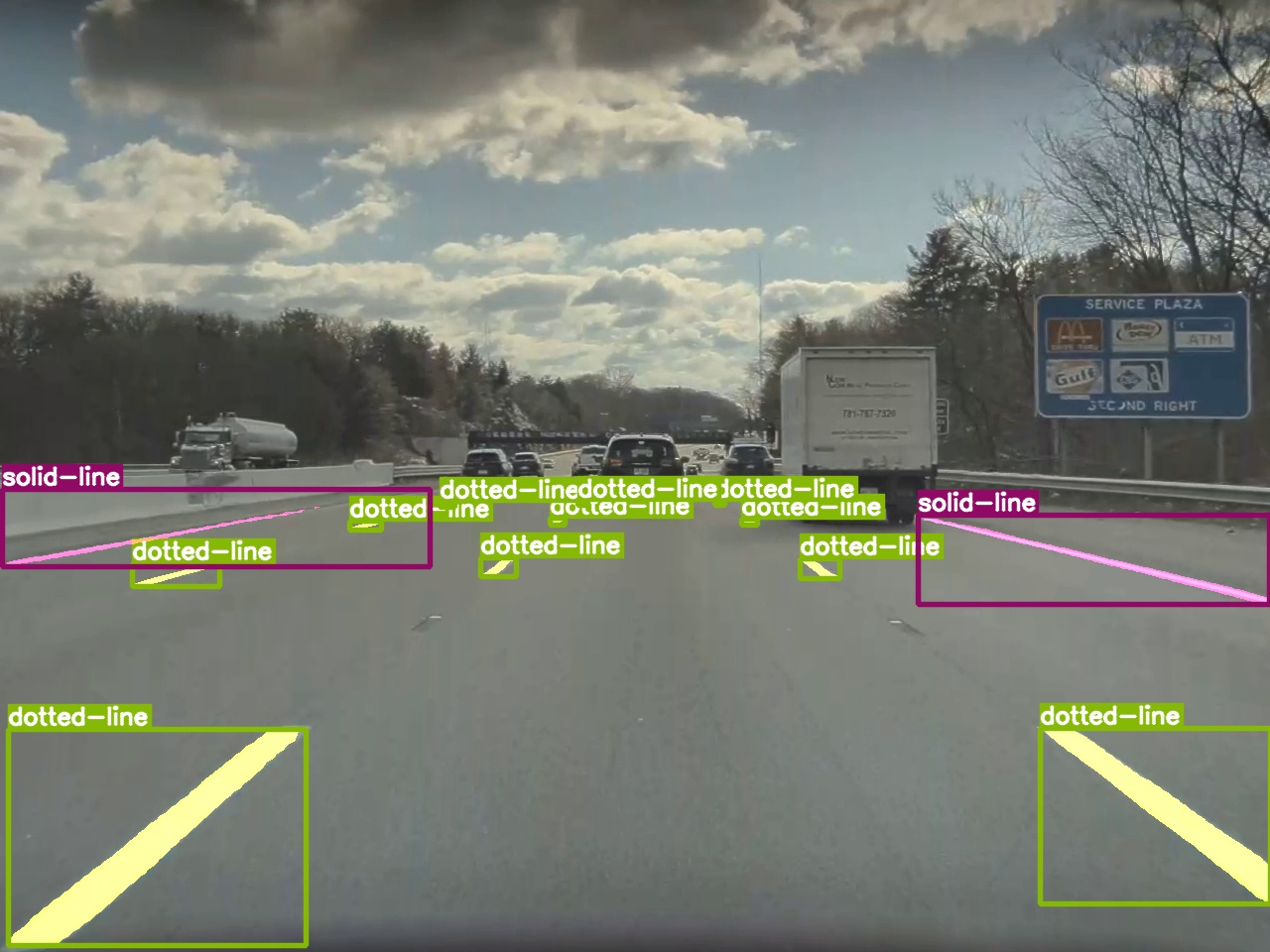
Lane Detection: Mask RCNN
We used this MASK RCNN trained on custom lane detection dataset from the given link for lane detection. This returns the type of lane i.e solid, dotted, divider line and double line which we use to plot them accordingly. We also get road-signs i.e signs on the road surface.
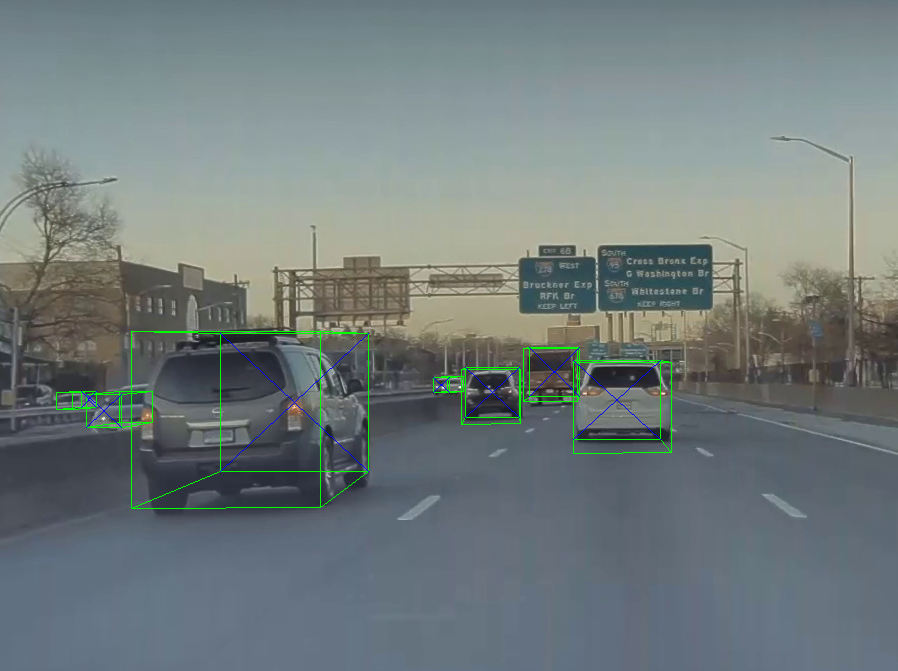
3D bounding box: For vehicle orientation
We use this implementation of YOLO3d to get the orientation of the vehicles. We pass the bounding boxes from DETIC to the regressor which predicts 3D bounding box. We use the yaw from this to spawn the cars with orientations.
Traffic Light detection: YOLOV3
We use this mdoel trained on LISA traffic light dataset fro traffic light detection. It detects go, goLeft, stop, stopLeft warning and warningLeft which we use to spawn the corresponding traffic light colors and arrows.

Road Signs detection: YOLOV8
We use the pretrained YoloV8 weights from the GLARE dataset paper for identifying various traffic signs like speed limit, pedestrain crossing etc. For speed bump detection we used a custom version of LISA dataset we found on ROBOFLOW and trained a YOLOv8 on that. It has a specific class for identifying speed bump signs. We aggregated the speed bump detections from this with the GLARE model.

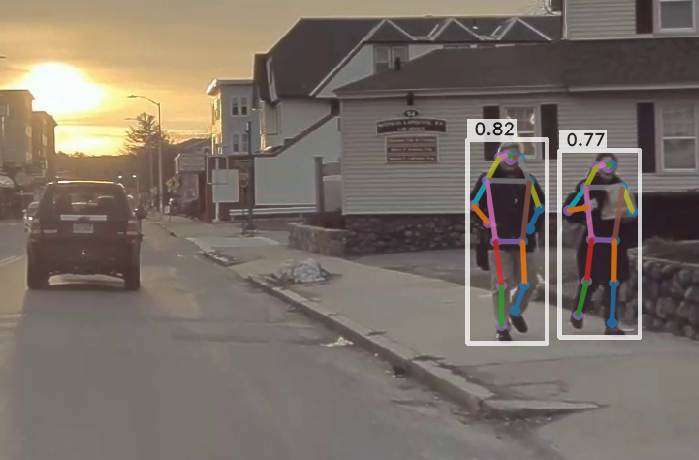
Human pose estimation: OSX
We use the OSX implemenatation which generates the blend file for the humans in the image. This captures intricate movements in a better manner.

RAFT: Optical Flow
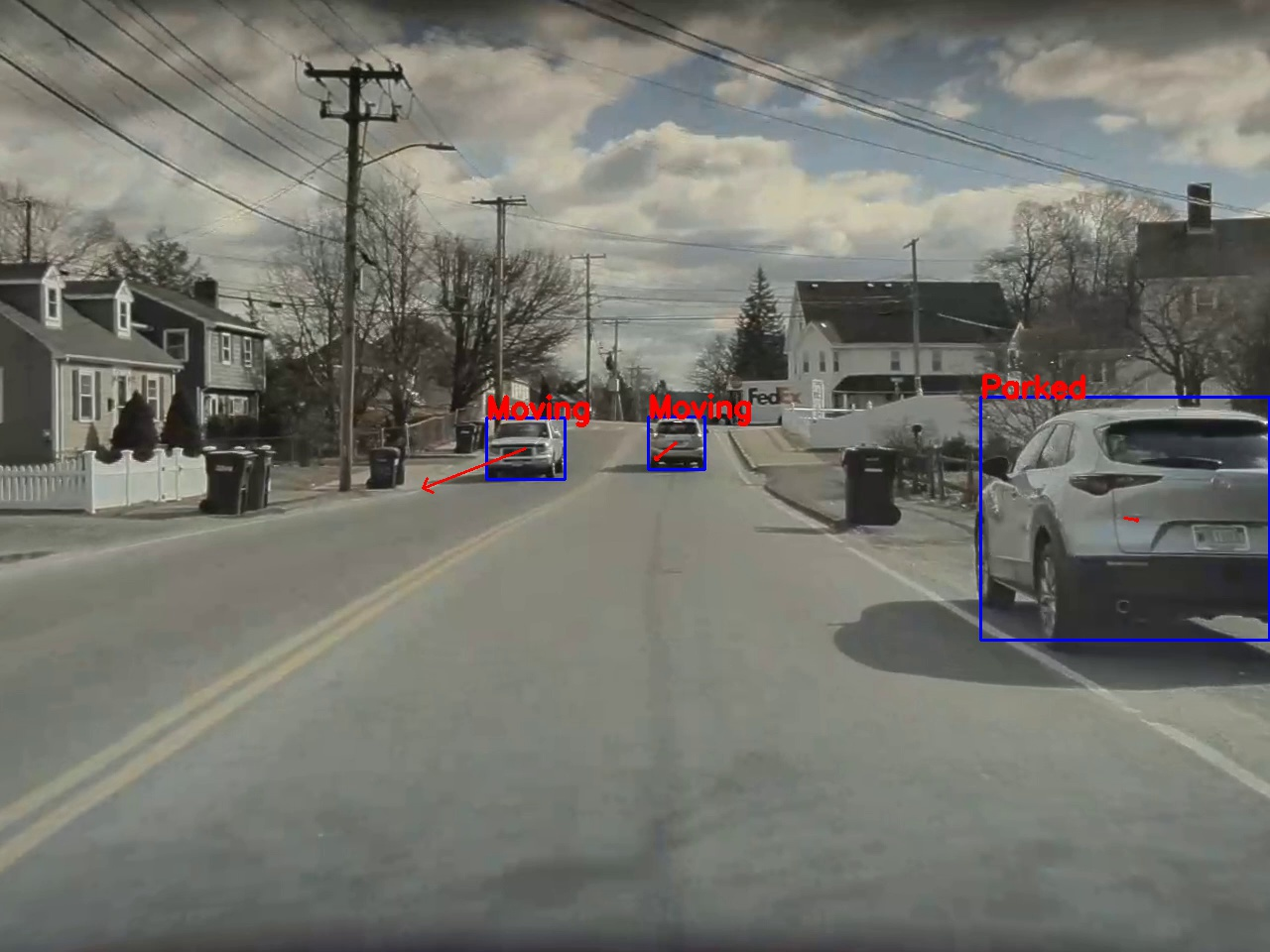
We use this to calculate optical flow which is used to identify if the car is moving or not. We use a classical apporach for tail light detection.

Parked and moving vehicles detections from optical flow.
Contributors: Mihir Deshmukh